工具介绍
obsidian web clipper 是由 obsidian CEO @kepano 开发的一款网络剪藏工具,完全开源,具有非常强的自定义功能,具体可参考官方指南。
我很喜欢 kepano 给它设置的口号(?),简洁有力,Save the web!
我虽然已经不再高强度使用 Obsidian,但受到象友启发,这个工具其实也可以非常好地服务 Logseq 等其他笔记工具。我会详细说一下我怎么针对 Logseq 进行一些设置。
特别说明一下,我看到 logseq 官方已经连夜 fork 了仓库,但是我看了一下代码,logseq 目前主要受限于他们的 url scheme 比较垃圾,所以功能上比较有限,我个人还是倾向使用 obsidian web clipper 进行手动剪藏。
保存豆瓣日记
- #To/Read [[{{selector:.note-header > h1}}]] #source/douban
- source:: {{selector:.note-container?data-url}}
- tags::
- author:: [[{{selector:a.note-author}}]] [Link]({{selector:a.note-author?href}})
- published_time:: [[{{selector:.pub-date|slice:0,19|date:("YYYY-MM-DD dddd", "YYYY-MM-DD HH:mm:ss")}}]]
- {{content|replace:"\n\n":"\n\n\t- "}}
这个方法没啥特别的,就是需要特别注意,我是剪藏到 logseq。所以,专门在最后一行,内容上进行一些替换操作,把段落都改成一个个节点,以及增加 \t tab 键把所有内容缩进放在标题之下。并且,日期呈现的格式,是按照我个人习惯调整的格式。
保存豆瓣广播(带图片链接)
- #To/Read [[{{selector:.status-title}}]] #source/douban
- source:: {{selector:#content > div > div.article > div.new-status.status-wrapper.from-detail.saying > div > div > div.hd?data-status-url}}
- tags::
- author:: [[{{selector:a.lnk-people}}]] [Link]({{selector:a.lnk-people?href}})
- published_time:: [[{{selector:.pubtime|date:("YYYY-MM-DD dddd", "YYYY-MM-DD HH:mm:ss")}}]]
- {{selector:div.status-saying > blockquote > p|replace:"\n\n":"\n\n\t- "}}
- pics
{{selector:.pics-wrapper .view-large?href|map: item => ""|template:"${str}"|replace:"/^!/gm":"\t\t- !"}}

总共有四部分内容
- 广播标题(并不是每一个广播都有标题,暂时还无法根据 selector 对应的 tag 是否存在而决定是否显示内容,在 discord 问了下,据说这个功能在计划中。)
- 各种 property,按需设置。
- 正文内容
- 图片区,豆瓣广播特色之一就是图片和正文是分开的,无法通过剪藏正文内容保存图片。
- 注意,我选择的是「原图链接」,如果想要豆瓣提供的缩略图(文件小,加载速度快,之后如果保存下来的话,文件小),将
.view-large?href部分替换成.upload-pic?src。
- 注意,我选择的是「原图链接」,如果想要豆瓣提供的缩略图(文件小,加载速度快,之后如果保存下来的话,文件小),将
我特别给出一个笔记结构图,是因为我不会为这些剪藏的内容专门创建 page,这个流程在 logseq 里不是特别方便,我会直接加入 journal。所以代码里面的空格、\t 代表 tab 缩进,都是为了能够将剪藏的所有内容都缩进保存在标题下面。
保存豆瓣图书 - 没有 HTML tag 怎么办
请允许我吐槽一下豆瓣非常杂乱的 HTML 结构,每个功能界面的结构、名称都不一样,哪怕是相似概念的内容。还有重要信息没放进任何 HTML 标签的情况。

比如上图中「出版年」三个字在 <span> 标签里,但是实际数据 2024-12-1 不在任何标签里。主要说一下豆瓣读书这个特殊情况如何获取到想要的信息。
{{selectorHtml:#info|remove_html:("span,br,a")|replace:"/^\s*/gm":""|split:"\n"|slice:3,4}}
这个方法有一个小问题,就是豆瓣数据有点小混乱,书籍提供的信息并不统一。「出版年」在上面这个选择器中出现的顺序可能不太一样。
可以进行手动调整,先在模板中删除 |slice:3,4 部分,返回的数据是下面这个格式:
["<div id=\"info\" class=\"\">","幽默有趣的人体维修指南","THIS BOOK MAY SAVE YOUR LIFE","2024-12-1","306","69.00元","平装","9787521769579","</div>"]
每条内容用 , 隔开,从 0 开始数,数到日期是第 3 个,那么就把 slice 后面的数字改为 3,4,再把删除的 slice 操作重新加上,即可选择出版日期。
授人以渔 - 怎么用 css selector
浏览器 inspector 用法
在 mac 上快捷键 cmd+shift+c 或 cmd+opt+i可以打开 chrome inspector。
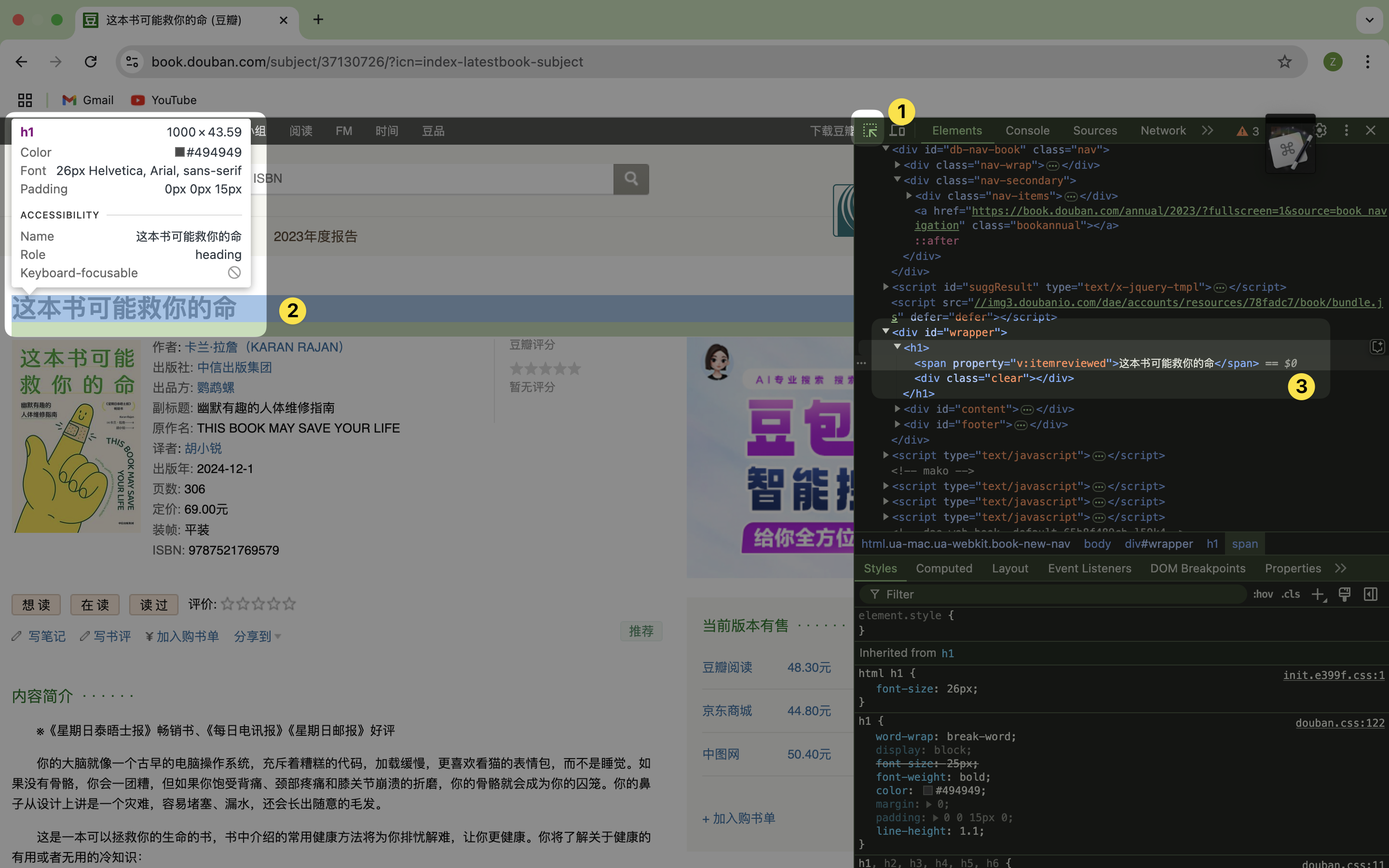
- 点击 inspector 最左上角的按钮就可以用来定位你想要剪藏的内容
- 滑动鼠标到你想要定位的内容,以这个图书标题来举例。
- 这时候 3 的位置就会定位这个元素在 HTML 文档中的位置,我们就可以观察一下它的结构。
一个小窍门
在 HTML 代码上右键可以轻松复制 selector。
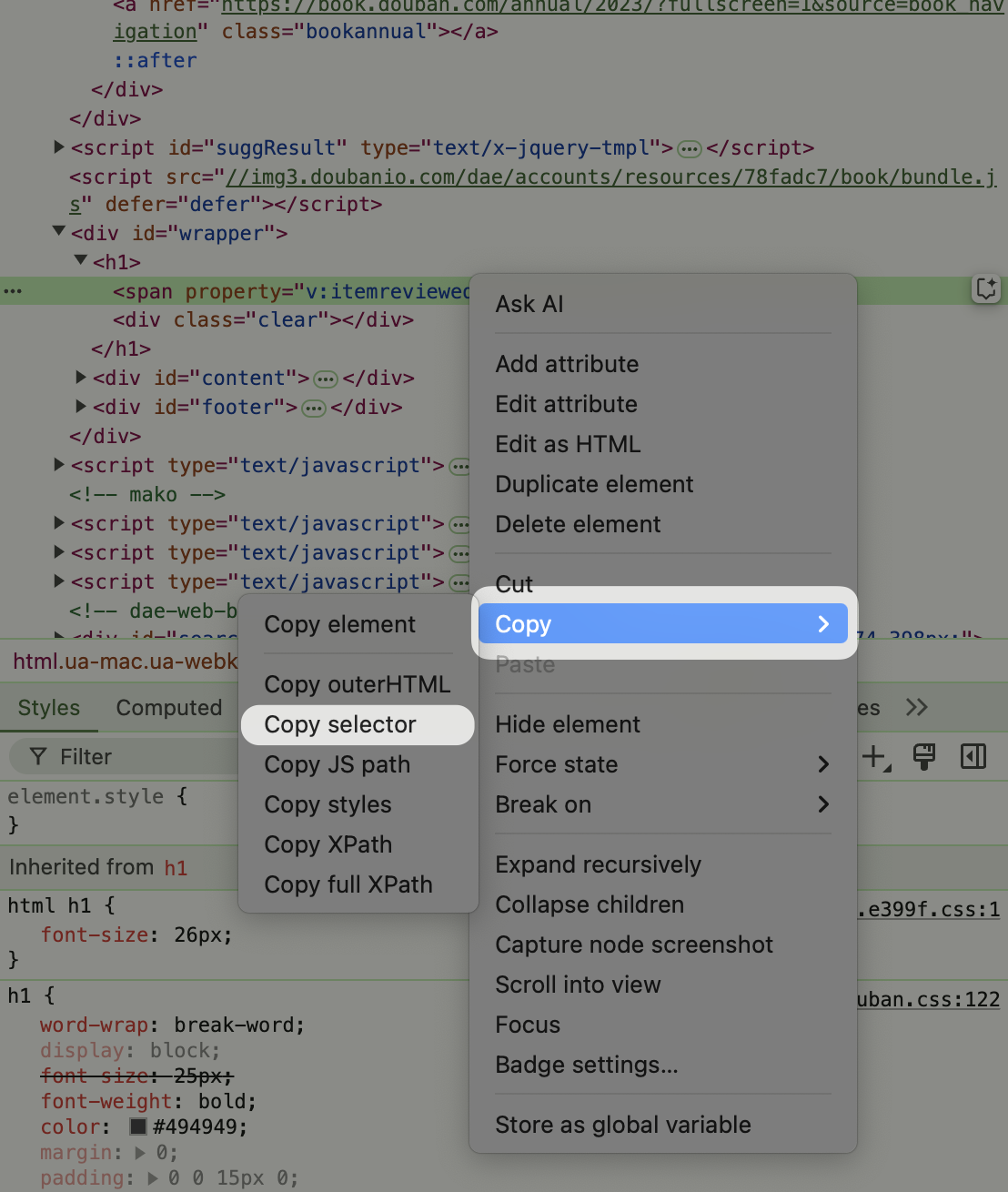
常见 css selector

从上图可以看到书籍标题内容「这本书可能救你的命」存在一个span 标签里,而这个标签紧跟着镶嵌在一个 h1 标签,h1 标签镶嵌在具有特殊 id 的 div 标签里。
可以先将这个具有特殊 id 的 div 标签选中,对于有 id 的元素选取方法是 # + id,所以就是 #wrapper.
定位直接子标签使用 > 连接,所以整体的 selector 就是 #wrapper > h1 > span。
非直接子元素则是用空格替代 >,比如前面保存豆瓣广播里所有的图片 .pics-wrapper .view-large,就是保存在 .pics-wrapper 元素内,不定位置出现的 .view-large 元素。
最后合起来的用法就是 {{selector:<put your selector here>}}
更新 - 带图片保存小红书网页版帖子
直接提供 json 文件,到插件设置界面导入即可。
小红书有一点比较烦人,日期格式变化莫测,暂时不想解决这个问题。
更新 - 带图片保存长毛象帖子
直接提供 json 文件,到插件设置界面导入即可。
暂时没有适配长毛象带有隐藏功能的内容。